
ComfyUI no es solo una interfaz; es un motor de ejecución gráfico que expone las entrañas matemáticas de los modelos de difusión. Para el usuario medio, los nodos son cajas que se conectan; para el arquitecto de flujos, son transformaciones de tensores en un espacio multidimensional.
Entender la arquitectura avanzada de ComfyUI marca la diferencia entre copiar workflows de otros y construir herramientas propias que resuelvan problemas concretos de producción. En esta guía, desglosaremos los conceptos que separan a los principiantes de los expertos. Si aún no tienes ComfyUI instalado, empieza por la guía de instalación en Windows.
Un ejemplo real de arquitectura avanzada
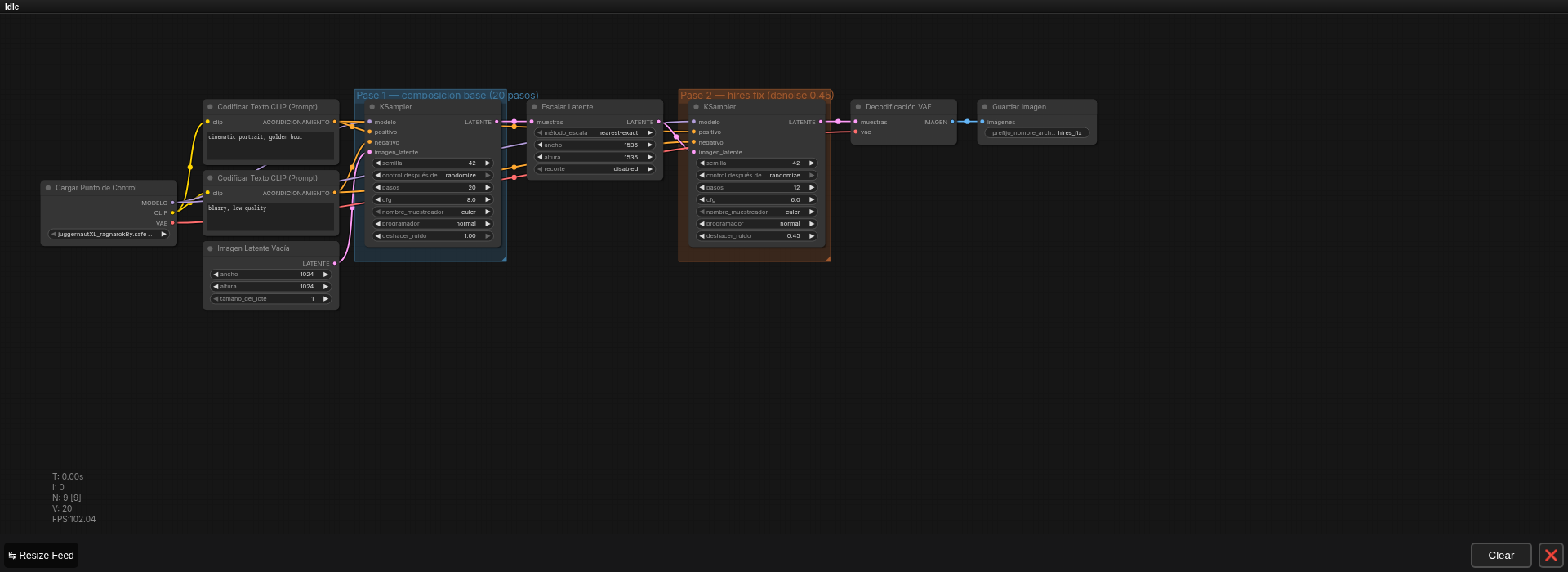 Workflow real de dos pasadas (hires-fix): composición base + refinamiento con upscale latente intermedio
Workflow real de dos pasadas (hires-fix): composición base + refinamiento con upscale latente intermedio
📡 Flujo Latente vs Flujo de Píxeles: El Gran Divisor
La mayoría de la confusión en ComfyUI proviene de no distinguir entre IMAGE y LATENT. Estos son los dos tipos de datos principales que manejamos.
📡 El Espacio Latente (The Latent Space)
Los modelos de difusión modernos no generan píxeles directamente. Trabajar con imágenes de alta resolución (como 1024x1024) sería prohibitivamente costoso en términos de computación. En su lugar, trabajan en un “espacio latente” comprimido.
En SDXL, por ejemplo, una imagen de 1024x1024 píxeles se representa como un tensor latente de 128x128 con 4 canales. Esta compresión de 8x permite que la GPU procese la información órdenes de magnitud más rápido. Cuando ves un nodo de color púrpura en ComfyUI, estás operando en este mundo matemático abstracto.
📡 El Espacio de Píxeles (The Pixel Space)
El espacio de píxeles es lo que percibimos. Los nodos de color azul/cian en ComfyUI representan imágenes reales. Aquí las operaciones son directas —recortar, redimensionar, filtrar— pero no es donde ocurre la generación de contenido nuevo por parte del modelo de difusión. El modelo ya terminó su trabajo antes de llegar aquí.
📡 El VAE: El Puente de Turing de la Difusión
El VAE (Variational Autoencoder) es quizás el componente más incomprendido. Su función es dual:
- VAE Encode (Compresión): Toma una imagen de píxeles y la “aplasta” en el espacio latente. Esto es necesario para tareas de Img2Img o Inpainting.
- VAE Decode (Descompresión): Toma el resultado del muestreador (KSampler) y lo “infla” de nuevo a píxeles para que podamos guardarlo como un archivo PNG o JPG.
Usar un VAE incorrecto es la causa número uno de colores lavados o artefactos extraños. Algunos modelos tienen el VAE integrado (Baked VAE), pero para otros, como SD1.5 original, es vital usar un nodo VAE Loader con un modelo como vae-ft-mse-840000-ema.
📡 Lógica de Condicionamiento: CLIP y la Semántica
Cuando escribes un prompt, no se lo estás enviando al modelo de difusión de forma directa. Primero pasa por el modelo CLIP.
📡 ¿Cómo funciona el CLIP Text Encode?
Este nodo transforma texto en un lenguaje que el UNet (el modelo de difusión) entiende. El proceso es:
- Tokenización: El texto se rompe en pedazos (tokens).
- Embeddings: Cada token se convierte en un vector numérico.
- Atención: Estos vectores se pasan al modelo, que decide qué partes del espacio latente deben verse influenciadas por cada palabra.
La arquitectura avanzada permite manipular este condicionamiento. Puedes sumar prompts (Conditioning Average), restar conceptos (Conditioning Set Area) o incluso aplicar prompts diferentes a distintas partes de la imagen antes de que el muestreador empiece a trabajar.
📡 Optimización de Flujos con Nodos de Control (Logic Nodes)
A medida que tus workflows crecen, se vuelven lineales y rígidos. La arquitectura avanzada introduce la lógica de programación en el lienzo gráfico.
📡 Nodos de Conmutación (Switches)
Los nodos de tipo “Switch” (disponibles en suites como Impact Pack o RGTHREE) dirigen el flujo de datos. Puedes tener tres tipos de Upscalers y usar un nodo de lógica para elegir cuál activar mediante un menú desplegable. Sin tocar un solo cable.
📡 Enrutamiento Inteligente
Si no usas Reroute y Set/Get Nodes (nodos inalámbricos), tu flujo se convierte en un laberinto de cables cruzados que nadie —incluido tú mismo tres semanas después— podrá seguir. Un arquitecto avanzado organiza su flujo en bloques funcionales:
- Bloque de Entrada: Carga de modelos y configuración de parámetros.
- Bloque de Proceso: Muestreo inicial.
- Bloque de Refinamiento: Hires Fix, Inpainting, o Detailers.
- Bloque de Salida: VAE Decode y guardado.
📡 El KSampler: El Corazón de la Iteración
El nodo KSampler (o SamplerCustom) es donde se ejecuta el algoritmo de desruidificación. Entender sus parámetros marca la diferencia entre resultados predecibles y horas perdidas ajustando a ciegas:
- Seed (Semilla): El punto de partida del ruido.
- Steps (Pasos): Cuántas veces el modelo intentará refinar la imagen.
- CFG (Classifier Free Guidance): Qué tanto debe “obedecer” el modelo a tu prompt de texto frente a su propia creatividad.
- Scheduler: Determina cómo se reduce el ruido en cada paso (ej. Karras, Exponential).
En arquitecturas avanzadas, usamos KSampler Advanced para controlar exactamente cuándo empieza (start_at_step) y cuándo termina (end_at_step) el proceso. Con ese control granular sobre los pasos, técnicas como el “Base + Refiner” de SDXL dejan de ser magia y se convierten en una decisión de diseño deliberada.
📡 Entendiendo el Orden de Ejecución del Grafo
A diferencia de un script lineal, ComfyUI es un motor de ejecución basado en grafos. El sistema analiza todo el lienzo y determina la ruta más corta para llegar a los nodos de salida. Dos consecuencias de esto que queman a los usuarios nuevos:
- Lazy Execution (Ejecución Perezosa): ComfyUI solo ejecuta lo que ha cambiado. Si modificas un prompt pero no la semilla (Seed), el sistema reutilizará el ruido latente previo, ahorrando tiempo de computación.
- Dependencias de Nodos: El grafo se recorre desde los nodos de salida hacia atrás. Si un nodo no está conectado a una salida (Save Image, Preview Image), nunca se ejecutará, por muchos recursos que consuma.
📡 Nodos Personalizados y el Sistema de Caching
La arquitectura de ComfyUI gana potencia real gracias a su sistema de caché. Cuando un modelo se carga en VRAM, permanece allí hasta que otro modelo requiere ese espacio.
📡 Optimizando con Custom Nodes
Suites como Efficiency Nodes o Impact Pack están diseñadas para consolidar múltiples transformaciones en un solo paso, reduciendo el overhead de la transferencia de datos entre nodos. Esto resulta decisivo cuando trabajamos con flujos complejos que involucran múltiples KSamplers y refinadores.
📡 El papel del Caching en la GPU
ComfyUI intenta mantener los tensores en la memoria de la GPU el mayor tiempo posible. Al diseñar workflows avanzados, agrupa las operaciones que usan el mismo modelo. Si alternas constantemente entre dos checkpoints diferentes dentro del mismo flujo, forzarás al sistema a vaciar y recargar la VRAM en cada ciclo. El resultado: tiempos de generación que pueden multiplicarse por diez respecto a un flujo bien ordenado.
📡 FAQ Técnica sobre Arquitectura
¿Puedo conectar un nodo LATENT directamente a un nodo IMAGE?
No. Debes pasar siempre por un nodo VAE Decode. Si intentas forzar la conexión mediante nodos de conversión de tipos, solo obtendrás errores de ejecución o resultados negros.
¿Qué es el ‘latent noise’ y por qué importa?
El ruido latente es el lienzo en blanco. En ComfyUI, el nodo Empty Latent Image crea este espacio. La resolución que pongas aquí define la relación de aspecto y el coste de memoria de toda la generación.
¿Cómo optimizo la VRAM en flujos complejos?
Usa nodos que permitan “liberar” memoria, como el Model Sampling Discrete. Además, evita mantener múltiples modelos grandes cargados simultáneamente si tu GPU tiene menos de 12GB de VRAM. ComfyUI gestiona la memoria de forma inteligente, pero un diseño de flujo consciente siempre ayuda.
¿Por qué mis nodos de lógica no se ejecutan?
ComfyUI es un grafo perezoso (Lazy Graph). Solo ejecuta los nodos que son necesarios para llegar a un nodo de “salida” (como Save Image). Si tu lógica no está conectada a nada que finalmente se guarde o se muestre, el motor la ignorará por completo.
Dominar la arquitectura de nodos es un viaje que comienza con la comprensión del espacio latente y termina con la creación de sistemas automatizados complejos. El curso experto en arquitectura de nodos es el siguiente paso lógico para dominar ComfyUI y empezar a diseñar tus propias soluciones de IA generativa. Si quieres profundizar en cómo los nodos interactúan con el hardware, nuestra guía de nodos esenciales te proporcionará la base necesaria.
Fuentes
Siguientes pasos en ComfyUI
Primeros pasos
Preguntas frecuentes
- ¿Cuál es la diferencia real entre el espacio latente y el espacio de píxeles?
- El espacio latente es una representación matemática comprimida (8 veces menor en SD1.5/SDXL) donde el modelo de difusión trabaja de forma eficiente. El espacio de píxeles es la imagen final que vemos. El VAE actúa como el traductor bidireccional entre ambos mundos.
- ¿Por qué mi imagen sale con ruido de colores si no uso un VAE?
- Sin un VAE (Variational Autoencoder), el sistema no puede decodificar la información latente en una imagen comprensible. El resultado es simplemente una representación visual de los datos comprimidos, que se manifiesta como ruido o patrones abstractos sin sentido.
- ¿Cómo influye el CLIP en la generación?
- El CLIP (Contrastive Language-Image Pre-training) transforma tus palabras en 'tokens' y luego en vectores matemáticos (embeddings). Estos vectores le dicen al modelo de difusión en qué partes del espacio latente debe 'esculpir' la imagen para que coincida con tu descripción.
- ¿Para qué sirven los nodos de lógica en un flujo de trabajo?
- Los nodos de lógica permiten crear workflows dinámicos que toman decisiones basadas en condiciones. Por ejemplo, puedes hacer que el sistema elija automáticamente un Upscaler diferente dependiendo de la resolución de la imagen de entrada o que cambie el modelo base según el estilo detectado.


